

This article comes from a presentation at Amazon Web Services. The presentation resonated with many of the people in the audience
The Happy Place
When it comes down to it, most people holding the title of ‘DevOps Engineer’ know how to get things going, are really good at making things work seamlessly (at least to the eye of business people), at automating deployments, and at doing the 24/7 support.
They are heavily relied upon by their managers and always get things done.
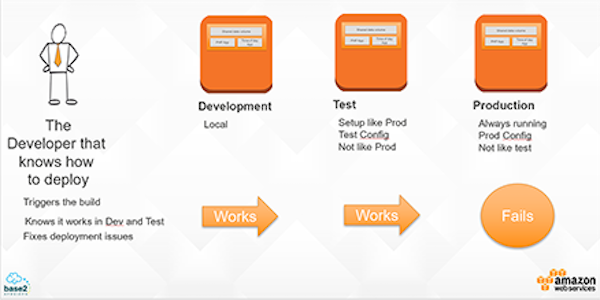
The DevOps Engineer has invested lots of time building the Production, Test, and Development environments. Over time, the configurations of those environments have differed slightly, but this hardly presents a problem because the DevOps Engineer knows exactly what needs to be done should a deployment ever fail.
Lets meet Lou
Lou is a fantastic DevOps Engineer who puts his heart and soul into his company, and sometimes even works through the night to get things done. He’s a great guy with a Developers’ sense of humour.
Lou decided he needed to take some time off work to spend at home with his family. (His family had suggested as much.) Suddenly,
- Production goes down after a deployment. The code had worked in development.
- The business calls Lou,
- Lou answers the call,
- Lou fixes the issue,
- Lou is not happy. He really didn’t want to focus on work. He needed a break. His family had insisted.
Lou quickly gets over it, but sincerely hopes that it does not happen again.
A couple months later, Lou requests more leave, deciding this time to take his family on a tropical holiday.
The S**t hits the fan
After a successful test cycle the development team is confident that everything is working as expected, so they push a new deployment to production. The services in production stop working. They try to fix it, but the services just keep on failing. Lou isn’t around to solve things quickly. The team has an emergency meeting and decides to roll back. However, nobody knows how to roll back. It’s not documented, and the only person who knows how to roll back is enjoying himself on a tropical holiday.
The business decides to call Lou, but Lou has listened to his family and has stopped paying any attention to his phone. They try for hours, ringing again, and again, and again. Production is down and customers are starting to complain.
Finally, several hours after production goes down, Lou checks his phone (because this is what DevOps engineers do). Lou calls his company, and to everyone’s relief they are up and running within 30 minutes.
The business has to fix this issue. Lou is just far too important to ever go on leave again.
What does the business fix?
The business knows it has a problem. They can’t rely on Lou never taking leave again, but hiring more Lou’s just isn’t in the budget. So, they decide to fix the deployment process and make sure that Development matches Test matches Production.
In theory, Lou could do this for his company. In reality, Lou is time-poor from looking after everything else and hasn’t yet developed enough skills to be effective. Even if Lou managed to fix the deployment process, he would still be the only one with the know-how to fix the deployment pipelines if they break again.
The business looks at finding consultants to come in and fix the issue. Unfortunately once this was done, they would again be left with Lou holding down the fort.
This is when they decide to look at DevOps as a Service. Not only would they get the development of the pipelines and environments done, but the service would also provide them with ongoing management, enhancements, break/fix and assistance. They would have a team, not just a person. A team to work closely with Lou to not only support the business, but to come up with new ideas that leverage their experience and ultimately make significant improvements to their company. They engage base2Services.
Automate deployments with confidence. Don’t just assume.
Everyone in the business, no matter their role, wants to be confident about the process and the approach. Each role has something different to be confident about, but essentially it comes down to things just working smoothly.
- The business wants to be confident that what they build and test will go to production with no issues – and at the very least be able to roll back.
- The developers want to know that the code works on the infrastructure.
- The testers want to give assurance that they tested everything.
- The users just want the solution to work.
What does Lou get?
Lou gets to work with a team that has huge insight into Cloud technology, available features, and the experience of over 300 migrations. He leverages this experience to improve his skill set and has a team that does the work for him.
Lou also gets time back. He no longer has to worry about the break/fix or deployment issues, and instead can put more time into features that benefit the company and its users. He does not have to worry about the day-to-day, and his work has become more project focused. But most importantly, Lou can take holidays when he wants to.

Just to recap
It took a major event for the business to fix an issue they originally ignored, hoping that things would just work. Once they decided to fix it, not only did they protect the business but they also made sure their developers could focus on the things that really mattered, developing new features for the product and gaining complete confidence in the deployment process.
Lou gets to take a break without putting the business at risk and can put more time into new capability (and his family).
Get in touch to find out how the DevOps as a Service value would be a cost benefit to you.